Understanding Transformers II - The Encoder
This post is a follow up to Part I on Decoders, you should start there if you are unfamiliar with decoders.
Recall that the Transformer architecture consists of three parts: the Decoder, the Encoder, and Cross Attention.
An encoder-only transformer looks like this:
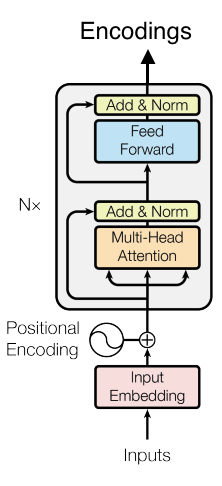
Encoder-only Transformers - BERT
Studying encoder-only transformers such as BERT (Bidirectional Encoder Representations from Transformers) (Devlin, 2019) allows us to understand encoders as a concept. Unlike decoder-only transformers which consume sentences and predict the next token, encoder-only transformers take sentences and encode them in a higher dimensional space. Encoders don’t do any prediction of next tokens or any meaningful task on their own. If we want them to do something like classification, we need to add task specific layers at the end of the model. For classification problems, this would be the classification head which would be some Multilayer Perceptron that consumes the encodings from the encoder blocks and outputs classification logits.
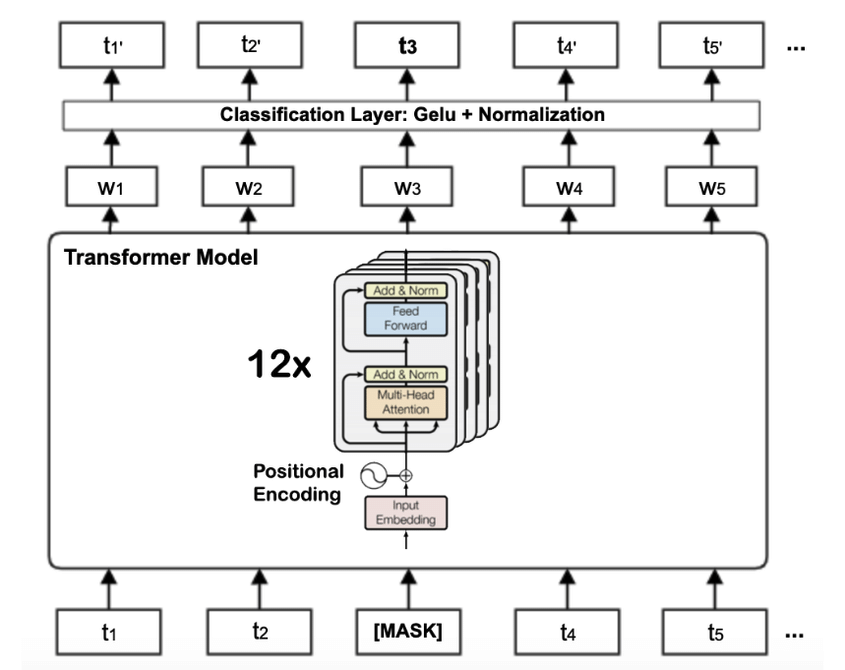
A key difference here between BERT and GPT-2 (decoder only) is that BERT consumes pairs of sentences. However this is just a choice of input, and is not necessitated by the architecture itself. A model like this can be broken down into simple steps, each corresponding to a part of the diagram above:
-
Receive an input sentence, consisting of two smaller sentences: “The cat is black. It licks its fur.”
-
Tokenization and embeddings: The process of tokenization and embedding the tokens is identical to that of decoder models. One additional step is we add a separator token (denoted SEP) between the two sentences.
- Positional encodings: Similar to the decoder-only transformer, we have positional vectors that we add to each token embedding to encode information about its position in the sentence. We also have segment encodings to indicate whether the token is in the first or second sentence.
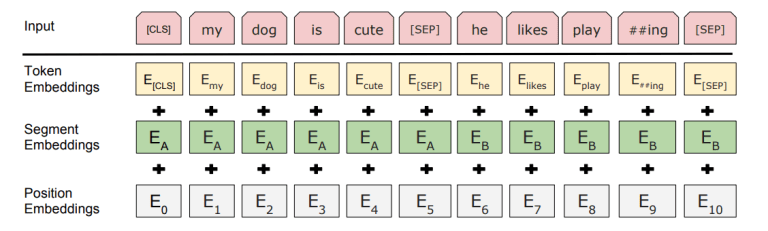 Figure 3. In BERT, we have both positional _and_ segment encodings (Devlin, 2019).
Figure 3. In BERT, we have both positional _and_ segment encodings (Devlin, 2019). -
Attention: This corresponds to the “Multi-head attention” box in the transformer diagram. The process is nearly identical to the “Masked Multi-head attention” mechanism in the Decoder block so I will not repeat its details here. Recall that attention is called masked when we disallow tokens from paying attention to tokens ahead of it in the sentence, by zeroing out these values. So, the only difference in the encoder case is we allow for tokens to pay attention to all other tokens in the input sentence, since the attention is not masked here. We have an Add and Normalize step after this is done to avoid vanishing gradient problems.
-
Identically to the Decoder case, we have a Feed Forward block where the attention value vectors are passed through a Multilayer Perceptron (MLP) to introduce non linearity. Once again we then do an Add and Normalize step.
-
Steps 4-5 constitute one transformer block. The outputs are then fed to the next block. This process can be repeated as many times as desired. In BERT’s case, this is repeated 12 times.
- At the output end of the last transformer block, we receive the encodings and can add any task head to fine tune the model to a specific task.
This completes the architecture.
References
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre‑training of deep bidirectional transformers for language understanding (arXiv:1810.04805). arXiv. https://doi.org/10.48550/arXiv.1810.04805
Khalid, U., Beg, M. O., & Arshad, M. U. (2021, February 22). RUBERT: A bilingual Roman Urdu BERT using cross‑lingual transfer learning (arXiv:2102.11278). arXiv. https://doi.org/10.48550/arXiv.2102.11278