Understanding Transformers III - Cross Attention
This post is a follow up to Part II on Encoders, you should start there if you are unfamiliar with encoders.
Recall that the Transformer architecture consists of three parts: the Decoder, the Encoder, and Cross Attention. In parts I and II we studied the decoder only transformer and the encoder only transformer, respectively. Now it is time to combine these things together to form the original encoder-decoder transformer architecture, using the Cross Attention mechanism.
Up to now, all mentions of “Attention” have referred to “Self Attention”, where a token pays attention to other tokens in the same sequence. Cross Attention is a mechanism where a token pays attention to tokens in a different sequence. In particular, Cross Attention is used to connect the Encoder and the Decoder.
How Cross Attention connects the Encoder and the Decoder
Something we should first clarify is how exactly the connection is made. The original diagram above is a bit confusing, but Murel and Noble (2024) provide a more clear explanation:
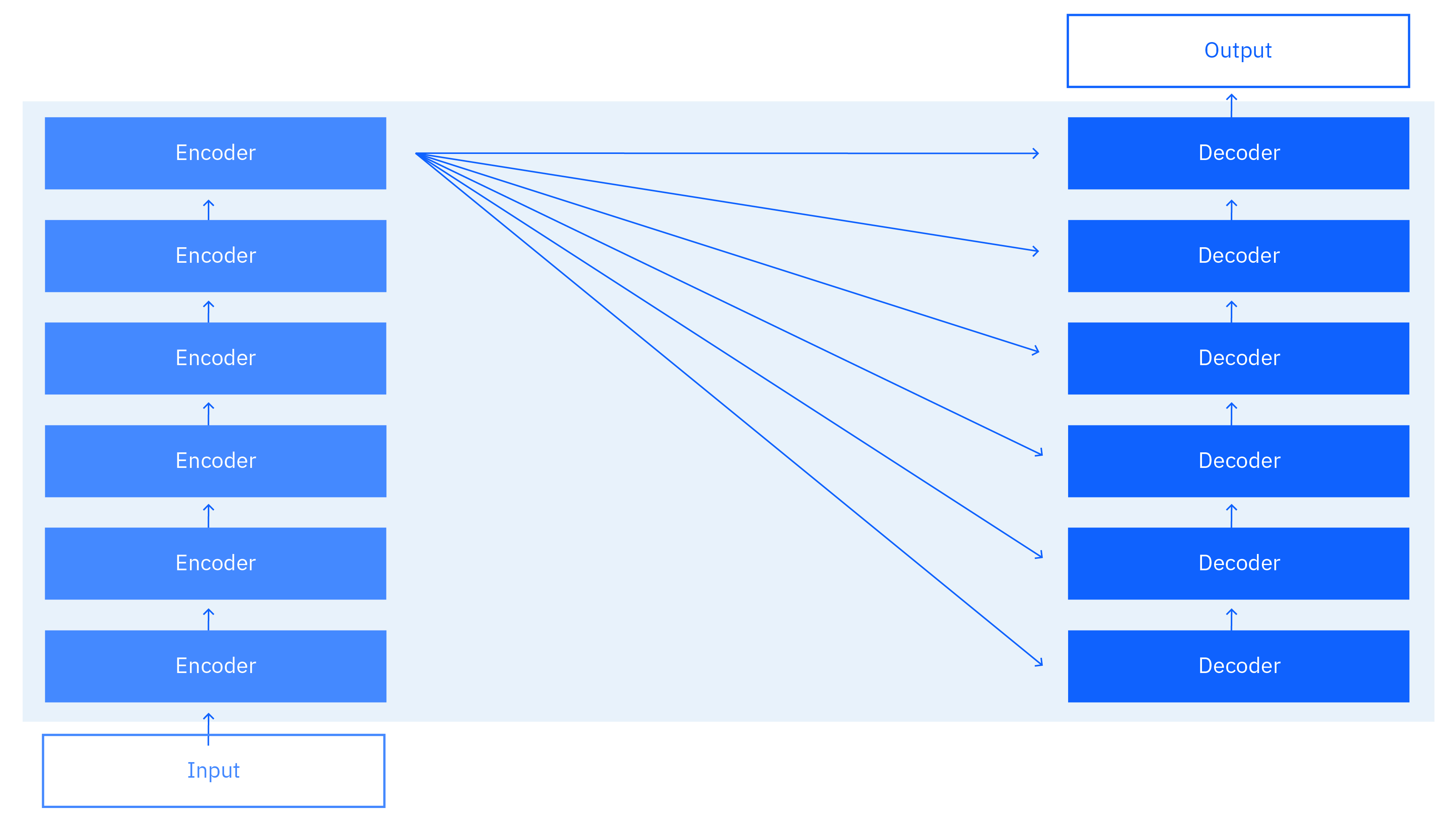
In words, once the encoder has processed the input sentence, the cross attention mechanism feeds the final encoding to each decoder block of the decoding stack.
The Cross Attention Mechanism in Detail
The cross attention mechanism is nearly identical to the self attention mechanism, the main difference now is that in Cross Attention, we port the Key and Value matrices over from the Encoder and the decoder uses its own Query matrix on these encoder matrices. This is illustrated in the diagram below:
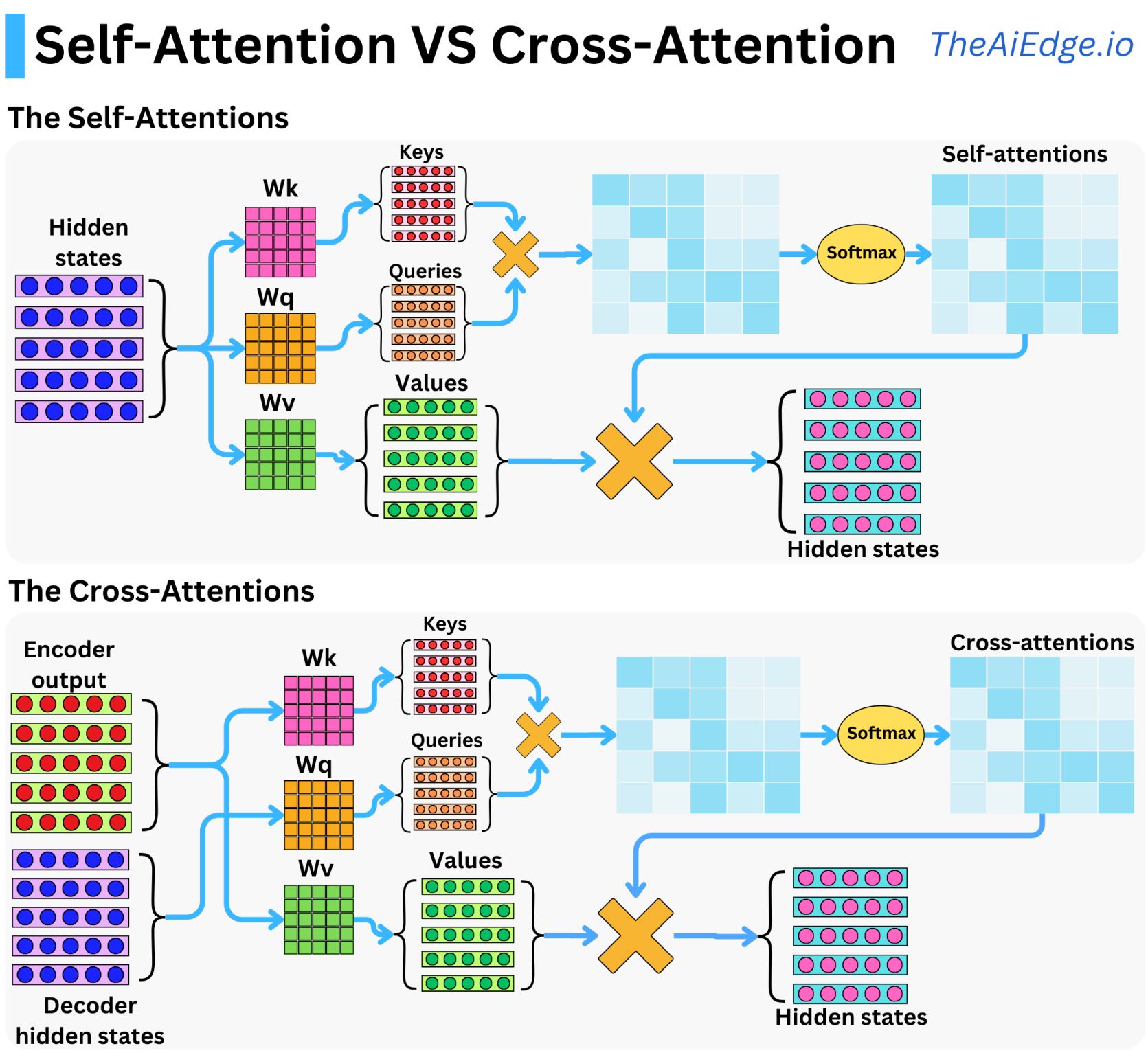
The math is entirely the same, the magic occurs just by the fact that we are reusing the Key and Value matrices from the Encoder and the Query matrix from the Decoder and performing this fancy rerouting.
But why?
Doing this allows each decoder block to pay attention to the final encoding of the input sentence. This is useful because it allows the decoder to use the information from the input sentence to help it generate the next token, and also prevents the decoder from “forgetting” the input sentence (vanishing gradient problem).
Conclusion
That’s it, that’s really all there is to the Encoder-Decoder Transformer.
References
Benveniste, D. (2024). What is the difference between self-attention and cross-attention? [LinkedIn post]. LinkedIn. https://www.linkedin.com/posts/damienbenveniste_what-is-the-difference-between-self-attention-activity-7211029906166624257-m0Wn/
Choi, J. (2024, March 2). Where the term “cross-attention” is first used? (couldn’t find the term in Attention is all you need paper) [Question on the Data Science Stack Exchange]. Data Science Stack Exchange. https://datascience.stackexchange.com/questions/128123/where-the-term-cross-attention-is-first-used-couldnt-find-the-term-in-attention-is-all-you-need-paper
Murel, J., & Noble, J. (2024). What is an encoder-decoder model? [Article]. IBM Think. https://www.ibm.com/think/topics/encoder-decoder-model